
 From advertising to IoT to healthcare and beyond, virtually all industries are adopting or investigating machine learning (ML) to benefit their business. But if both you and your competitor are adopting ML, what do you need to do to get an edge? The Two Sides of ML ML (as a term) is used to refer […]
From advertising to IoT to healthcare and beyond, virtually all industries are adopting or investigating machine learning (ML) to benefit their business. But if both you and your competitor are adopting ML, what do you need to do to get an edge? The Two Sides of ML ML (as a term) is used to refer […] 
From advertising to IoT to healthcare and beyond, virtually all industries are adopting or investigating machine learning (ML) to benefit their business. But if both you and your competitor are adopting ML, what do you need to do to get an edge?
The Two Sides of ML
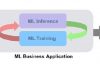
ML (as a term) is used to refer to both business applications of this technology and to the technology itself and its underpinnings of algorithms, models and predictions. Applying ML for business benefit requires both the ML training (a.k.a model generation, model build or model fit) that generates the model and the ML inference (a.k,a prediction, scoring, or model serve) that generates the insights. These ML inferences need to be integrated into the business use case, creating an ML business application that ultimately generates the customer value.
These two elements (ML Training and ML inference) do not exist in isolation. There is always a cycle that connects them (see Figure). Models generated by Training need to be sent to Inference, and (immediately or eventually) the experiences of live data have to be used to further optimize the model in the next round of training. In recent history, sometimes this cycle has taken months or years, and as such it was almost possible to forget the cycle even exists. However, now with advances in training algorithms [1], powerful hardware [2,3], and scalable analytic engines [4], runtimes for each phase have been substantially reduced.
Competitive Business Value: Closing the Loop
The primary purpose of most ML initiatives is to convert insight into business value (whether it is by recommendations, optimizations, fault detections etc.) The tighter the execution of this cycle, the quicker the business can respond to changing circumstances. For example, by quickly learning a user’s immediate shopping pattern and correlating it to notable events of the day, a business can generate better shopping recommendations and drive more sales. Many other examples of the value of quick adaptation exist [5,6]. As more businesses adopt ML, competitiveness will be determined by not just whether you adopt ML, but whether you can turn this cycle around and adapt your ML faster than your competitor.
Sounds simple enough in concept, but why is it difficult to put into production practice? Although sophisticated ML algorithms and many data scientist tools exist, putting ML into production (and continuously integrating new retraining) is still a challenge since it requires integrated discipline and practice between Operations, Data Science, and sometimes Business Analysts.
- Expertise Mismatch: On one side, IT operations administrators are experts in deployment and management of software and services in production. On the other side, data scientists are experts in the algorithms and associated mathematics. Operating ML/DL in production and deploying new models requires the combined skills of both groups and their respective processes.
- Non-Intuitive Complexity: In contrast to other analytics like rule-based, relational database or pattern matching key-value based systems, the core of ML/DL algorithms are mathematical functions whose data-dependent behavior is not intuitive to most humans. This complexity requires custom algorithmic knowledge beyond standard operations for diagnostics, test and optimization.
- Regulatory and Process needs: As ML becomes a more critical function in business applications, there is a greater need to manage and track the process by which new ML models become deployed and drive outcomes. Depending on the industry, there are emerging regulations and practices in this area as well [7,8].
As more and more ML algorithms become available and open source analytic engines and GPUs make fast ML possible for all forms of data, the bottleneck to getting practical business value moves to the production challenges above.
Learning from Past Examples: Database Administration
ML is a complex application. Another great example of a complex application in production is a database. As databases grew in popularity, the software world introduced a role of “Database administrator”, recognizing that this complex application in production required a combined skill set which included both deep knowledge of the database and its architecture/technology, and experience with production operations (uptime, resource management, non-disruptive changes etc.). Today databases are at the core of virtually all production operations and it is impossible to imagine them functioning without a DBA.
ML can benefit from this analogy. Managing production ML and sustaining the cycle above requires the combined (very different) skills of both data scientists (experts in algorithmic behavior) and operations (data architects etc.).
Learning from Past Examples: DevOps
Another relevant key trend is DevOps. Different definitions exist depending on who you ask, but at the core, DevOps is a philosophy and set of practices that drive a seamless integration between development and operations. Beyond the Continuous Integration/Continuous Deployment (CI/CD) model, DevOps creates an integrated practice where quick turn cycles of new application software versions can be reliably and collaboratively pushed into production.
Introducing MLOps
MLOps (a compound of Machine Learning and “information technology OPerationS”) is new discipline/focus/practice for collaboration and communication between data scientists and information technology (IT) professionals while automating and productizing machine learning algorithms. Via practice and tools, MLOps aims to establish a culture and environment where ML technologies can generate business benefits by rapidly, frequently and reliably building, testing, and releasing ML technology into production.
MLOps captures and expands on previous operational practices while also extending them to manage the unique challenges of Machine Learning
- The need to combine two very different skill sets. In ML, it is the data scientist (skilled in algorithms, mathematics, simulations, developer tools etc.) and the operations administrator (skilled in production rollouts, upgrades, resource and data management, security, etc.).
- The need to roll out new models and algorithms seamlessly with no downtime. Production data changes patterns due to unexpected events. ML predictions based on trained models respond well to previously seen scenarios. As such, frequent retraining (or even online continuous training) can make the difference between an optimal prediction that factors in recent history and a suboptimal prediction.
We at ParallelM believe that this discipline, MLOps, which draws from previous models like DevOps but extends to address unique ML needs, is critical for businesses to close the loop and generate highly adaptive and competitive ML business applications. Our products are focused on driving and supporting the MLOps lifecycle.
A business’ ability to optimize MLOps can determine how quickly it can adapt to changing circumstances relative to competition. We believe MLOps is the next competitive frontier in the rapidly expanding ML business applications space.
By Nisha Talagala, Co-Founder, CTO & VP Engineering, ParallelM.
References:
[1] https://www.sciencedaily.com/releases/2017/11/171113123641.htm
[3] https://semiengineering.com/the-next-phase-of-machine-learning/
[4] https://jaxenter.com/whats-new-tensorflow-1-4-138769.html
[6] https://www.datasciencecentral.com/profiles/blogs/top-9-machine-learning-applications-in-real-world