
Coopetition and AI Self-Driving Cars
 By Lance Eliot, the AI Trends Insider Competitors usually fight tooth and nail for every inch of ground they can gain over the other. It’s a dog eat dog world and if you can gain an advantage over your competition, so the better you shall be. If you can even somehow drive your competition out […]
By Lance Eliot, the AI Trends Insider Competitors usually fight tooth and nail for every inch of ground they can gain over the other. It’s a dog eat dog world and if you can gain an advantage over your competition, so the better you shall be. If you can even somehow drive your competition out […]
 By Steven Levy, Wired When asked to head Facebook’s Applied Machine Learning group — to supercharge the world’s biggest social network with an AI makeover — Joaquin Quiñonero Candela hesitated. It was not that the Spanish-born scientist, a self-described “machine learning (ML) person,” hadn’t already witnessed how AI could help Facebook. Since joining the company in […]
By Steven Levy, Wired When asked to head Facebook’s Applied Machine Learning group — to supercharge the world’s biggest social network with an AI makeover — Joaquin Quiñonero Candela hesitated. It was not that the Spanish-born scientist, a self-described “machine learning (ML) person,” hadn’t already witnessed how AI could help Facebook. Since joining the company in […] Whether it’s a navigation app such as Waze, a music recommendation service such as Pandora or a digital assistant such as Siri, odds are you’ve used artificial intelligence in your everyday life. “Today 85 percent of Americans use AI every day,” says Tess Posner, CEO of AI4ALL. AI has also been touted as the new must-have […]
Whether it’s a navigation app such as Waze, a music recommendation service such as Pandora or a digital assistant such as Siri, odds are you’ve used artificial intelligence in your everyday life. “Today 85 percent of Americans use AI every day,” says Tess Posner, CEO of AI4ALL. AI has also been touted as the new must-have […] Alibaba Group Holding Ltd. is in talks with BT Group PLC about a cloud services partnership as the Chinese internet giant challenges Amazon.com Inc.’s dominance in Europe. An agreement between Alibaba and the IT consulting unit of Britain’s former phone monopoly could be similar to Alibaba’s existing arrangement with Vodafone Group Plc in Germany, according […]
Alibaba Group Holding Ltd. is in talks with BT Group PLC about a cloud services partnership as the Chinese internet giant challenges Amazon.com Inc.’s dominance in Europe. An agreement between Alibaba and the IT consulting unit of Britain’s former phone monopoly could be similar to Alibaba’s existing arrangement with Vodafone Group Plc in Germany, according […] The world of artificial intelligence is frightening. No, not the danger of an army of AI-powered robots taking over the world (though that is a bit concerning). The real fear is that the wrong vendor is chosen or the rollout handled poorly. After all, AI is complex, not fully mature, in some cases poorly understood, and […]
The world of artificial intelligence is frightening. No, not the danger of an army of AI-powered robots taking over the world (though that is a bit concerning). The real fear is that the wrong vendor is chosen or the rollout handled poorly. After all, AI is complex, not fully mature, in some cases poorly understood, and […]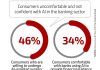 There are about 7.5 billion people on the planet, give or take a few. But that number pales in comparison to the number of connected devices worldwide. According to Autonomous, a financial research firm, people are outnumbered three-to-one by their smart computing devices — an estimated 22 billion in total. And the number of smart devices will […]
There are about 7.5 billion people on the planet, give or take a few. But that number pales in comparison to the number of connected devices worldwide. According to Autonomous, a financial research firm, people are outnumbered three-to-one by their smart computing devices — an estimated 22 billion in total. And the number of smart devices will […] According to a McKinsey report, only 20% of companies consider themselves adopters of AI technology while 41% remain uncertain about the benefits that AI provides. Considering the cost of implementing AI and the organizational challenges that come with it, it’s no surprise that smart companies seek ways to test the solutions before implementing them and get […]
According to a McKinsey report, only 20% of companies consider themselves adopters of AI technology while 41% remain uncertain about the benefits that AI provides. Considering the cost of implementing AI and the organizational challenges that come with it, it’s no surprise that smart companies seek ways to test the solutions before implementing them and get […]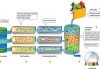 By Lance Eliot, the AI Trends Insider How do you learn something? That’s the same question that we need to ask when trying to achieve Machine Learning (ML). In what way can we undertake “learning” for a computer and seek to “teach” the system to do things of an intelligent nature. That’s a holy grail […]
By Lance Eliot, the AI Trends Insider How do you learn something? That’s the same question that we need to ask when trying to achieve Machine Learning (ML). In what way can we undertake “learning” for a computer and seek to “teach” the system to do things of an intelligent nature. That’s a holy grail […] By Lance Eliot, the AI Trends Insider Earlier in my career, I was hired to reverse engineer a million lines of code for a system that the original developer had long since disappeared. He had left behind no documentation. The firm had at least gotten him to provide a copy of the source code. Nobody […]
By Lance Eliot, the AI Trends Insider Earlier in my career, I was hired to reverse engineer a million lines of code for a system that the original developer had long since disappeared. He had left behind no documentation. The firm had at least gotten him to provide a copy of the source code. Nobody […] Artificial intelligence (AI) is increasingly getting attention from enterprise decision makers. Given that, it’s no surprise that AI use cases are growing. According research conducted by Gartner, smart machines will achieve mainstream adoption by 2021, with 30 percent of large companies using AI. These technologies, which can take the form of cognitive computing, machine learning and deep learning, are now […]
Artificial intelligence (AI) is increasingly getting attention from enterprise decision makers. Given that, it’s no surprise that AI use cases are growing. According research conducted by Gartner, smart machines will achieve mainstream adoption by 2021, with 30 percent of large companies using AI. These technologies, which can take the form of cognitive computing, machine learning and deep learning, are now […]