
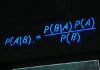 By. Dr. Lance Eliot, AI Trends Insider Is it going to rain tomorrow? If you were to answer that question, would you say that it absolutely positively will rain tomorrow? Or, would you say that it absolutely positively won’t rain tomorrow? Here in Southern California, we only get about 15 days of rain during the […]
By. Dr. Lance Eliot, AI Trends Insider Is it going to rain tomorrow? If you were to answer that question, would you say that it absolutely positively will rain tomorrow? Or, would you say that it absolutely positively won’t rain tomorrow? Here in Southern California, we only get about 15 days of rain during the […] 
By. Dr. Lance Eliot, AI Trends Insider
Is it going to rain tomorrow?
If you were to answer that question, would you say that it absolutely positively will rain tomorrow? Or, would you say that it absolutely positively won’t rain tomorrow? Here in Southern California, we only get about 15 days of rain during the year, and so most of the time I’d be safest to say that it won’t rain tomorrow. But, I’d be wrong on those 15 or so days of the year. If I were to say that it will definitely rain tomorrow, I’d normally be wrong, unless of course I had some kind of inkling that it might be a rainy day. The weather forecasters do a pretty good job of predicting our rain, and so if they indicated that it most likely would rain tomorrow, it’s a relatively safe bet for me to say that it will rain tomorrow.
Now, if the weather forecast predicts that it will rain tomorrow, should I consider the prediction to be a one hundred percent absolutely certain prediction? Usually, the weather forecasts are accompanied by a probability. For example, the rain forecast might be that there’s a 70% chance of rain tomorrow. In that case, I likely would feel comfortable claiming that it would rain tomorrow since the percentage being at 70% seems pretty high and suggests that it will rain. On the other hand, if the forecaster had said it was about a 10% chance of rain tomorrow, I’d likely feel that the percentage was too low and so I’d hedge and say it might rain but that it might very well not rain.
I realize that all of this talk about the weather might seem rather obvious. We all intuitively understand that the rain forecast involves probabilities. We take it for granted that there is some amount of uncertainty about the weather predictions. In a sense, the weather predictions are a form of gambling, whereby we don’t know for sure that something will happen, but we are willing to make bets based on the odds that something might happen.
As humans, we are continually having to perform reasoning under uncertainty. Sometimes we try to calculate actual probabilities, while other times we just go with a hunch or intuition. Whenever you go to Las Vegas and play the slot machines or a game of poker, you abundantly know that you are using probabilities and that you are gambling. It’s obvious because you are in a place and context that everyone accepts as a gamble. What are the odds that the next card dealt at the blackjack table is a King? What are the odds of the slot machine hitting on the jackpot?
There’s another place and context in which we do a lot of gambling and deal with probabilities. It’s called driving a car. Yes, when you drive a car, you are essentially gambling. You are making a bet that the car will start, and that you will be able to drive the car on the highway and not get hit by another car. You are making a whole slew of gambles for every moment you are driving in your car. Yet, being a driver in a car seems so commonplace that we don’t think of it as a gamble.
When that car ahead of you starts to tap on its brakes, are you thinking about the probability that the car is going to next slam on their brakes? Are you calculating the odds that the car behind you will be able to stop in time? Did the chances of getting smashed between the car ahead of you and the car behind you leap into your mind? For most people, they aren’t silently doing those kinds of probability calculations per se. They have instead learned over time to make judgements about those odds. On some days, you maybe ignore some of those probabilities and push your risks higher. Other days, you become more conscious of the odds and are at times ultra-careful as you drive.
When making predictions, you have some predictions that are made before you even get behind the wheel of the car. Suppose you look out the window of your office and see that rain is pouring down. I would wager that you begin to think about your drive home from work, and that besides dreading the traffic congestion and the slippery roads, you are already adjusting the gambles and probabilities of the driving task. You know that a car can slip and slide on wet streets, and so you are going to take on heightened risk of crashing your car during the drive home. You know that other drivers are often careless in the rain, and so the odds that someone might plow into your car is increased.
All of that takes place in your mind before you get into the car. Once you are in the car, you begin to update your predictions. Pulling onto the highway, if you see that the road is flooded, and you see that there are some cars that have already slid off the road, you are bound to increase your own probability about the potential for getting into a car crash of some kind. You continually are updating your earlier predictions, adding and subtracting from the probabilities as you go along. The collection of new information allows you to gauge how good or bad your earlier predictions were, and you then adjust them accordingly.
Some of the new evidence will be quite useful and bolster your ability to make predictions. This so-called strong evidence might be that you can see other cars around you that are having great difficulty navigating the rain. You might also have weak evidence, such as seeing a pedestrian on the side of the road that has stepped into a deep puddle. The pedestrian isn’t near your car and there’s nothing specific related to your driving task, but it might be a reminder of the potential for puddles of water and the dangers that puddles have if they are say in the middle of the roadway.
Some statisticians like to suggest that there are two camps of probabilities calculations. One camp is known as the frequentist group, or also referred to as the direct probability strategy approach. They prefer to assign probabilities based on the chances of outcomes in similar cases. For example, I might tell you that 1% of cars get into car crashes during the rain. Thus, when you go to your car to drive in the rain, you might be assuming that you have a 1% chance of getting into a car crash on the way home.
The other camp instead thinks about conditional probabilities. They assert that the probability for something will be changing over time and that with each step you need to adjust your probability assessment. When you start that drive home in the rain, suppose the rain was really no more than a very light sprinkle and there wasn’t any water sitting on the roadways at all. Perhaps the chances of your getting into a car crash are less than the 1%, maybe only one-tenth of one percent. Furthermore, maybe your car has heavy duty tires and was made to drive in rainy conditions. Again, this could reduce your chances of getting into a car crash in the rain.
So, we have the frequentists that consider the long-term frequencies of repeatable events and look at the world in a somewhat generic manner, and we have the conditional probability camp that says a particular situation dictates the nature of your probabilities. In a moment, we’ll take a close look at one of the most famous elements of the conditional probability camp, namely the Bayesian view of probability.
We are all used to the idea that probability is usually measured via a value between zero and one. The numeric value between 0 and 1 is a fraction, and so we often for ease of communication turn those values into percentages. I had earlier mentioned that a rain forecast had been a 70% chance, which we also know could be expressed as a probability of 0.70.
Perception is often vital to ascertaining probabilities.
There’s a popular point made in statistics classes that if you roll a dice (one die) that presumably you have a 1 in 6 chances of picking the correct number that will end-up at the top of the dice at the end of the roll (that’s one divided by 6, which is .166 or about a 17% probability). That prediction assumes that the dice is a “fair” dice that has the numbers 1 through 6 on each face, and that the dice is not weighted purposely to skew the roll, and that the roll itself will not somehow be done in a manner that can skew the results. We assume that over many rolls of the dice, we will only have each of the numbers come up with a chance of 17%. Of course, in the short-run, we might have several of the same numbers come up over and over, but in the long-run over maybe hundreds or thousands of rolls, we’d expect the 17% chance to occur.
Suppose that you secretly knew that the dice was loaded such that the number 4 will never end-up on the top. You would know that the odds are more like 1 in 5 of your guessing the roll, or 20% probability, which is better than the “fair” dice odds of 1 in 6. A person standing next to you that does not know what you know about the dice would have a perceived odds of 1 in 6, while you would have a perceived odds of 1 in 5.
In this sense, we say that the uncertainty is epistemological, it is a probability that will be based on the agent’s knowledge of how the world is.
What does all of this have to do with AI self-driving cars?
At the Cybernetic Self-Driving Car Institute, we are pushing ahead on the use of probabilistic reasoning for AI self-driving cars.
Today, most of the self-driving cars that the auto makers and tech firms are developing have not yet been developed with probabilities imbued into the AI systems. I realize this might seem like a somewhat shocking statement. Given that human driving involves continually gauging and adjusting probabilities and dealing with uncertainty, you would expect that the AI of self-driving cars would be doing likewise.
That’s generally not been the case, as yet.
Part of the reason for this lack of embracing probabilities into the reasoning for the AI of self-driving cars involves the aspect that doing so is not as easy as it might seem at first glance.
For many conventional systems developers, they aren’t used to embedding uncertainty into their software. They write programs that are supposed to deal in absolutes. If you are writing code to calculate how much taxes someone owes, you aren’t thinking about whether the tax calculation is correct with an 85% chance of being correct. Instead, you are thinking in terms of absolutes. The tax calculation is either absolutely right or absolutely wrong.
Another factor involves whether the public will accept the concept that their self-driving car is dealing with uncertainties. People want to believe that the self-driving car is always going to be absolutely correct. If they knew that the system on-board was calculating probabilities and was willing to take that left turn up ahead but had calculated that it was only a 75% chance that the turn could be navigated without rolling the car, they might decide they don’t want to be in a self-driving car.
Once probabilities are immersed in the systems of the self-driving car, there are bound to be regulators and lawmakers that will ultimately want to know what those probabilities are. And, if there are car crashes, you can bet that the legal teams, juries, and judges involved in handling lawsuits about car crashes are going to want to know how the probabilities were calculated and whether they were “reasonably” acted upon by the AI.
What makes the use of probability in AI even tougher is that we don’t especially have the proper tools and programming languages available for that purpose. There are very few programming languages that can readily make use of probabilities. If you are an AI developer, and even if you know about probabilities and want to include it into your coding, you have few viable choices of robust enough programming languages for that purpose.
Indeed, a recent effort by Uber has brought forth a new programming language they are calling Pyro. The Uber AI Labs is trying to make Pyro into the programming language of choice for anyone doing AI that also needs to deal with probabilities in their code. It’s an open source programming language and only in its infancy, so we’ll have to see how the adoption of it proceeds. It ties to Python, which will aid it in gaining popularity, and uses the PyTorch library and Tensor. Keep in mind that there are other Probabilistic Programming Languages (PPL) available for developers, such as Edward and also WebPPL, but those have yet to become widely popular. They tend to be used more so by researchers and those that are “in the know” about the importance of probability in programming.
Here’s an example excerpt of some illustrative Pyro code that involves dealing with the probability that we might have a 70% chance of rain and that on rainy days there’s a 10% chance of accidents while there’s a 1% chance on non-rainy days:
Def rainy():
rain = pyro.sample (‘rainfall’, dist.bernoulli, Variable(torch.Tensor ([0.70]) ))
rain = ‘rainfall’ if rain.data[0] == 1.0 else ‘dry’
accident_chance_avg = {‘rainfall’ : [10.0], ‘dry’ : [1.0] } [rain]
accident_chance_variation = {‘rainfall’ : [3.0], ‘dry’ : [0.2] } [rain]
table_chances = pyro.sample (‘table_chances’ dist.normal,
Variable (torch.Tensor(accident_chance_avg)),
Variable (torch.Tensor(accident_chance_variation))
Return rain, table_chances.data[0]
We could then setup additional code that invokes the function and inspects or use the various outputs we’d get out of the stochastic distribution by referring to this rainy function.
I had mentioned earlier that the Bayesian approach is a significant element of the conditional probability camp. For those of you that vaguely know Bayes theorem, it provides a handy mathematical formula that can be used to determine the probability of events as based on predictive tests (which are often referred to as “evidence” but you should be cautioned that the word “evidence” in this case has a somewhat different meaning than what you customarily might think the word means in everyday parlance).
Let’s suppose that we had a 1% overall long-term chance of getting into a car crash (meaning that we have a 99% overall long-term chance of not getting into a car crash).
Let’s further suppose that we have developed in the AI for the self-driving car a function Z that tries to assess the current situation of the self-driving car and combines together sensory data to gauge whether a car crash seems to be a potential chance or not. We’ll for now say that this special test Z has an 80% chance of predicting a car crash. This of course also means that it has a 20% chance of not predicting a car crash.
Like any such test, it can sometimes also produce a false positive, which means that it sometimes predicts that there will be a car crash and yet the car crash does not occur. Let’s assume that this test has a 10% chance of making that kind of a prediction.
Here’s what we have so far:
Event: Car Crash 1% overall chance
Test Positive: True Positive 80% chance
Test Negative: False Negative 20% chance
Event: Car Won’t Crash 99% overall chance
Test Positive: False Positive 10% chance
Test Negative: True Negative 90% chance
The AI of the self-driving car wants to answer this question: What is the probability of a Car Crash event occurring if we get a positive test Z result from the special function?
This can be represented as this: P(A|Z)
P means we want to determine the probability. The letter A refers to the Car Crash event. The vertical bar means “given that the test prediction has occurred.”
We can use Bayes theorem, which is: P(A|Z) = ( P(Z|A) x P(A) ) / P(Z)
In this case:
P(Z|A) = 80% = 0.80
P(A) = 1% = 0.01
P(Z) = (1% x 80%) + (99% x 10%) = 0.008 + 0.099 = 0.107
And so:
P(A|Z) = ( P(Z|A) x P(A) ) / P(Z) = ( 0.80 x 0.01 ) / 0.107 = 0.075 = 7.5%
Notice that in this scenario, the chances of the car crash are only about 7.5%, which though we can certainly be worried, it isn’t so high that we might believe a crash is imminent in the circumstances.
Part of the reason it’s seemingly low is that the false positive of the test Z was at 10%. If we could improve the special function so that it had a much lower false positive, it would be a more handy test.
Let’s assume we do some more work on the special function and we get it down to having just a 1% false positive rate. If so, the P(A|X) in this scenario would become 0.447, in other words it would be a 44.7% chance. This would be hefty enough that the AI of the self-driving car would want to find ways to avoid the car crash since it would seem to present a much more significant chance of happening.
There are going to be probabilities associated with all facets of the self-driving car, including:
- Sensor data collection
- Sensor fusion
- Virtual Model updates
- AI action plan formulation
- Car controls activation
- Tactical AI
- Strategic AI
- Self-aware AI
To reach a true Level 5 self-driving car, meaning a self-driving car that has AI that can drive the car as a human can, the use of uncertainty and probabilities will need to be incorporated into the AI system. Doing so will not be easy, and the AI developers need to be careful about how they make use of probabilities. They will need a solid understanding of how to calculate and utilize probabilities. There will need to be some very clever means of examining how the probabilities are being used and promulgated throughout the AI system. Etc.
Probabilistic reasoning is not solely needed for the AI in self-driving cars. On a more macroscopic scale, it is generally believed by some in the AI field that probabilistic reasoning is needed to make AI become increasingly “intelligent” and that without which we will hit another barrier of AI that might not be overcome. Combining other machine learning techniques with probabilistic reasoning seems to be a smart way to get us toward the true meaning of AI. I’ll take odds on it.
This content is originally posted on AI Trends.

You must be logged in to post a comment.