
 By Lance Eliot, the AI Trends Insider During the Cold War era, the Soviet military doctrine was one of strict control by the central Soviet command. All decisions about the use of military force had to be first approved by Soviet commanders at the highest levels of the hierarchy, and there was little if any […]
By Lance Eliot, the AI Trends Insider During the Cold War era, the Soviet military doctrine was one of strict control by the central Soviet command. All decisions about the use of military force had to be first approved by Soviet commanders at the highest levels of the hierarchy, and there was little if any […] 
By Lance Eliot, the AI Trends Insider
During the Cold War era, the Soviet military doctrine was one of strict control by the central Soviet command. All decisions about the use of military force had to be first approved by Soviet commanders at the highest levels of the hierarchy, and there was little if any latitude afforded to local commanders. With a massive military force consisting of over 53,000 tanks, 4,900 aircraft, and some 360 submarines, the Soviet top authorities wanted to make any and all decisions regarding military actions. You might think that this seems like a very prudent policy, since it would presumably prevent local commanders from taking rogue actions.
The counter-argument to this approach was that it meant that the Soviet ability to act quickly was substantively degraded. Local commanders that might be aware of a local situation brewing were obligated to report up the chain to the top command, and then had to wait to take any action until specifically authorized to do so. In contrast, the American military allowed for some autonomy by its local commanders, meaning that the USA forces could potentially be nimbler and quickly act or react to an emerging situation.
If you’ve ever seen the movie “Crimson Tide,” you might recall that a crucial scene in the movie (spoiler alert!) involves the USS Alabama nuclear submarine and the dynamic tension between the Captain and the XO of the ship. A message had come via radio from the Naval command that the sub should go ahead and arm its nuclear missiles and fire them within a set time frame. But, a second message then comes to the sub, and the message is only partially received. Should they proceed based on the first message which was entirely received and very clear cut, or should they perhaps not proceed since the second message was inadvertently cut-off and could have been an order to desist and not fire the nuclear missiles. The Captain and the XO get into quite an argument about what they should do.
Decisions at a local level can have life-or-death consequences.
How does this relate to AI self-driving cars?
At the Cybernetic Self-Driving Car Institute, we are advancing the use of edge computing for AI self-driving cars. Edge computing is a relatively newer term and has become increasingly important as the era of the Internet of Things (IoT) has begun blossoming.
Edge computing is the idea and approach that sometimes the computer processing and algorithmic decisions need to occur at the extrene edge of a computer network. Rather than having processing and algorithmic decisions being made in the cloud, the notion is to push the intelligence and computing closer to the action. This allows for immediacy of analysis.
Imagine if you have a factory that is being run by all sorts of automated pumps and turbines. If the equipment is connected to the cloud, and if all of the data coming off those devices goes up into the cloud, it would be tempting to also have the cloud actually controlling those devices. When a pump needs to be turned-off, a command issued from the cloud, through a network, and down to the pump would tell it to switch off. When a pump is having troubles, it would send a message through the network and up into the cloud. This would be a centralized way of managing the equipment.
Suppose though that the pump begins to have a problem and it takes a bit of time for it to communicate through the network, and then for the network to convey the message to the cloud, and then there’s time that the cloud application needs to process the information, and then issue a command, which goes through the network, and finally reaches to the pump. It could be that the pump by then has gone completely haywire. The delay in the steps from pump-cloud-pump might have taken so long that the cloud missed the chance to save the pump.
With the advent of the Internet of Things (IoT), this kind of consideration is going to become increasingly prominent and important. The Gartner Group, an IT research firm, estimates that there were 8.4 billion IoT devices in 2017, and by the year 2020 there will be 20.4 billion IoT devices in use. Those IoT devices will need to communicate with the cloud, and the cloud itself might become increasingly bogged with traffic, thus, adding further to delays between the cloud and the IoT devices communicating with the cloud.
Any IoT devices that have life-or-death consequences, such as medical IoT devices in the home, could put humans at risk.
This could also be said of self-driving cars. Self-driving cars have lots of sensory devices on them, including cameras, LIDAR for laser or light radar use, sonar devices, and so on. Many of the self-driving car makers are envisioning that the data from the sensors will flow up into the cloud that the auto maker has setup for their self-driving cars. This allows the auto makers to collect tons of driving data and be able to use machine learning to improve AI self-driving practices.
The question arises as to how much of the processing should take place at the “edge,” which in this case is the self-driving car and its myriad local devices, versus taking place in the cloud.
For practical reasons, we already know that much of the processing has to occur at the edge, since the speed by which the sensory data needs to be analyzed is bound by the fact that the self-driving car is in motion and needs timely indications of what is around the car. Estimates suggest that a self-driving car that runs eight hours a day (which is a fraction of what is ultimately expected, i.e., we assume that eventually they will be operating 24 hours per day), would produce at least 40TB of data (according to Intel). That’s a lot of data to be transmitting back-and-forth over a network.
Estimates also suggest that sending data back-and-forth across a network would take at least 150-200 milliseconds, assuming that there is a strong network connection and that the connection remains continuous for the time to make the transmission. That’s actually a huge amount of time, given that the car is in motion and that rapid decisions need to be made about the control of the car. In some respects, if the cloud is calling the shots, it is like the Soviet military doctrine and would likely cause delays, perhaps life-or-death delays.
Therefore, self-driving cars need to make use of edge computing. This involves having enough localized computational processing capability and memory capacity to be able to ensure that the self-driving car and the AI are able to perform their needed tasks. You might be saying that we should just go ahead and put lots and lots of processors and memory on-board the self-driving cars. That’s a nice idea, but keep in mind that you are going to be adding a lot of cost to the self-driving car, plus adding equipment that will eventually be breaking down and need maintenance, and that requires power to run, and adds weight to the car, etc.
So, we need to be thoughtful and judicious as to how much localized processing needs to be done. Keep in mind too that it is not necessarily a mutually exclusive proposition of local versus cloud. A well-designed AI self-driving car will be able to mix together the localized processing and the cloud processing.
For example, the self-driving car might be processing the sensory data in real-time and taking driving actions accordingly. Meanwhile, it is sending the data up to the cloud. The cloud processes the data, looking for longer-term patterns, and eventually sends down to the self-driving car some updates as based on doing an analysis of the data. In this case, we’ve split the effort into two parts, one that is doing the life-or-death rapid processing at the local (edge) level, and the more overview oriented efforts at the cloud level that aren’t particular time sensitive in nature.
The ability to push data up to the cloud and get back results will be dependent upon:
* Communication devices on the self-driving car
* Latency involved in communicating via a network
* Bandwidth of a network
* Availability of a network
* Reliability of a network
* Communication within the self-driving car
Notice that this depends on the nature of the network and network connection that the self-driving car has established for use. When you think about your network at home and how it at times has hiccups and delays, it is a bit disconcerting to think that the network of the self-driving car might also be based on the Internet and the vagaries that go along with that kind of network. This is why it makes sense to not base the self-driving car real-time efforts on the cloud per se.
There are some devices on the self-driving car that would be considered edge-dedicated, meaning that they are completely reliant on their own local efforts. They don’t care about the cloud. Though data they collect might be sent up to the cloud, they aren’t dependent upon anything coming back from the cloud. There are edge-shared devices that are able to split efforts with the cloud, undertaking some tasks entirely locally and other tasks in a joint collaborative manner with the cloud.
Doing image analysis on pictures streaming in from a camera on the front right bumper of the self-driving car is something likely best done at the edge. The image analyzer on-board the processors of the self-driving car would be looking for indications of other cars, motorcycles, pedestrians, and so on. This is then fed into the sensor fusion, bringing together the sensory analyses coming from the LIDAR, radar, etc. The sensor fusion is being fed into a virtual world model of the surrounding driving scene. All of this is being undertaken at the edge (in the self-driving car).
The AI of the self-driving car is running on local processors in the self-driving car, and interprets the virtual world model to decide what actions to take with the car. And, the AI then commands the car controls to accelerate or brake, and steers the car. We would anticipate that by-and-large this all takes place at the edge.
Here’s how it looks:
Sensor data collection at the edge
Sensor fusion at the edge
Virtual world model update at the edge
AI action plan determined at the edge
AI issues car-control commands at the edge
Self-driving executes the car-control commands at the edge
We could instead include the cloud as a non-real-time collaborator, meaning that the cloud would be kept apprised of what’s happening, but would not be undertaking control related to the self-driving car:
Sensor data collection at the edge
Send data up to the cloud, but don’t wait for the cloud
Sensor fusion at the edge
Send sensor fusion result up to the cloud, but don’t wait for the cloud
Virtual world model update at the edge
Send virtual world model up to the cloud, but don’t wait for the cloud
AI action plan determined at the edge
Send AI action plan up to the cloud, but don’t wait for the cloud
AI issues car control commands at the edge
Send AI-issued car control commands up to the cloud, but don’t wait for the cloud
Self-driving car controls executive the commands
Get updates from the cloud and update the edge when feasible
We’ve interlaced the transmitting of the edge information up to the cloud. This could also be done instead at say the end of the above loop, rather than trying to interlace it.
If you were to decide to put the cloud control into these steps, here’s how it might look:
Sensor data collection at the edge
Send data up to the cloud, wait for the cloud
Sensor fusion at the cloud
Virtual world model update at the cloud
AI action plan determined at the cloud
AI issues car control commands via the cloud
Wait until the cloud car-control commands are received
Self-driving car executes the car-control commands
In this above edge-cloud model, the self-driving car is pretty much a “dumb” car and not doing much of any real processing on its own. As previously mentioned, the concern here is whether or not the communication would be reliable enough and consistent and fast enough for what needs to be done. The cloud itself might have some of the fastest computers on earth, but in the end it is the network communication that could undermine that hefty processing power.
One of the values of using the cloud would be the ability to leverage the much larger processing and memory capacity that we could have in the cloud versus what we’ve got loaded onto the self-driving car. For example, when I mentioned that doing image analysis from pictures streaming in is best done at the edge, it could be that there is a massive scale learning-in-the-cloud capability that has thousands upon thousands of images from thousands upon thousands of self-driving cars, and it might be able to do a better job of image analysis than some smaller neural network sitting on a processor at the edge.
Thus, well-designed self-driving cars are able to have the autonomy needed at the edge, and also leverage the cloud when appropriate. We might for example have the self-driving car AI get updates from the cloud when the self-driving car is available to do so, such as maybe when the car is parked and otherwise not being used. It could enhance a local edge-based neural network, doing so via leveraging the larger-scale neural network learnings from the cloud.
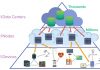
There are some that believe we also need fog computing.
Fog computing is the middle-ground between edge computing and cloud computing. We might have intermediary computing that acts as a go-between for the edge and the cloud. This might mean that we’d have computer servers setup along the roadways, and those systems could much more quickly and reliably communicate with self-driving cars that are whizzing along on the highway than would the cloud per se. Thus, you get presumably a cloud-like capability that won’t have the same kinds of latency and issues as the true cloud. This requires adding a lot of infrastructure, which would tend to be costly at both initial setup and keeping it maintained.
In the fog model, you have edge-fog-cloud as the elements involved, rather than just edge-cloud. Some are doubtful about the fog approach, and though the name itself is kind of clever, some also say that the name won’t catch-on (since the word “fog” seems to have a bad connotation). The jury is still out about fog computing.
Developers of self-driving cars are finding that they need to carefully consider how edge computing is best arranged for self-driving cars. This will be an evolving innovation and we are likely to see the AI self-driving car first-generation, we’ll call it 1.0, gradually become version 2.0, making self-driving cars better able to be both standalone as needed and yet also leverage the cloud as needed.
This content is originally posted on AI Trends.
Click here for the Podcast version of this column.