
 By Dr. Lance Eliot, the AI Trends Insider When my son was very young, he and I played a board game that he seemed specially to enjoy. It required concentration and dexterity, and a bit of imagination along with a dose of excitement. If you made a mistake during the game, there would be a […]
By Dr. Lance Eliot, the AI Trends Insider When my son was very young, he and I played a board game that he seemed specially to enjoy. It required concentration and dexterity, and a bit of imagination along with a dose of excitement. If you made a mistake during the game, there would be a […] 
By Dr. Lance Eliot, the AI Trends Insider
When my son was very young, he and I played a board game that he seemed specially to enjoy. It required concentration and dexterity, and a bit of imagination along with a dose of excitement. If you made a mistake during the game, there would be a directly adverse reaction by the game. In some cases, if your action was really a lousy choice during the game, there would be a substantial clatter and reaction. Naturally, he didn’t like losing the game and so tended to enjoy it more when others made a blunder rather than he. I recall that when I picked the wrong piece and caused the rest of the pieces to nearly “explode” upward, he would jump for joy. It’s that competitive spirit in our DNA, I’m sure.
You might be familiar with the board game, called Booby Trap, which was quite popular in the 1960s when it first came out and still today can be found in most toy stores. The game involves placing various wood pegs into a bounded area of a small wooden platform and then using a spring-loaded bar to push together the pegs.
Essentially, the pegs are crammed together once the spring-loaded bar is put in place and the pegs are so sandwiched that they can be hard to pull out of the platform. And that’s indeed the notion underlying the game, namely that you take turns with other players in trying to pull out pegs from the platform. If you can pull out a peg without having the spring bar move, or at least not move more than a stated distance, you earn points based on the designated value of that peg. The larger pegs are worth more points, of course, since they are more likely when extracted to potentially cause the spring-loaded bar to shift.
From a cognition and growth perspective, I played the game with my son and also my daughter as not only a means to have fun, but also since I figured it would be a good learning tool for them. One aspect of learning in this particular game is the effects of compression. When you compress items together, you need to think about how the physics of compression impacts other objects. In some instances, the compression would bear upon a handful of the pegs and the other pegs were not under any pressure at all. This at first was counter intuitive to my children as they initially assumed that applying pressure would cause all of the pegs to be under pressure. They mentally caught on and were then able to quickly determine which of the pegs weren’t under pressure, and would lift those out when their turn during the game play occurred, thus avoiding the risk of having the spring-loaded bar move.
They also learned about the act of pruning. Removal of each of the pegs is essentially a type of pruning action. You are lessening the number of objects involved in the game play. The more you did of pruning, the harder the game play became, due to the aspect that you now had less pieces that were in a confined area and that were the only ones left holding the spring-loaded bar in place. If you went too far in your pruning, the spring-loaded bar would shift and you’d lose points. It took both a delicate hand and a sharp mind to be able to play this game.
Why care about this game? Well, it’s a great introduction to some of the most important core elements of computer science. When storing data, you tend to not have unlimited storage space and therefore need to be thinking about how you can reduce the amount of data and yet still keep intact the meaning that the data represents. If you prune out the data overly so, you might have reduced the volume of data but at the same time you might have tossed out essential aspects and the loss is a bad thing. Likewise, you can try to keep the data around and rather than pruning it you might compress it. Compression compacts things together and can reduce the total amount of space, but at the same time you need to consider how readily you can get access to the data since it will require decompression to put it back into a readable state.
As an aside, I realize that some of you might be thinking that I was maybe a bit too serious with my children while playing games. I assure you that we played games for sport and fun! All I am saying is that the games themselves also provided handy lessons in life. Why not leverage those handy lessons and either consider that they will occur subliminally, and the child won’t even realize what is taking place, or perhaps instead try to explicitly get the proverbial one-bird-with-two-stones. You can have your child play a game for both fun and for gaining new knowledge and lessons in life.
Anyway, let’s get back to compression and pruning. Sometimes you only focus on pruning. Sometimes you only focus on compression. Sometimes it is handy to do both compression and pruning. From a computer viewpoint, the act of compressing and pruning can be computationally intensive and so you need to decide whether there is a valid Return on Investment (ROI) for doing so. If the effort to compress and prune is one-time, and then the result is used over and over, the cost to do the one-time upfront compressing and the pruning is more likely to be worthwhile. You are potentially able to reduce the amount of storage required overall and the compactness might allow for the data to be more easily and less expensively stored.
What does this have to do with AI self-driving cars?
At the Cybernetic Self-Driving Car Institute, we are using deep compression and pruning for machine learning to be able to have neural networks that are more compact and usable in self-driving cars.
The pruning of neural networks goes back to some of the earlier days of the advent of artificial neural networks. Numerous studies during the 1990s attempted to find ways to prune neural networks. The overarching idea is to consider all possible neural network topologies that apply to the problem at hand, and choose from these variants the one that has the same output at the smallest size. Unfortunately, trying to go through all possibilities to find the “best” one is generally infeasible due to the vast number of combinations and permutations that would need to be examined. As such, there are various pruning rules-of-thumb that have been developed that guide toward doing a less comprehensive pruning and yet also aim at trying to find a smaller sized neural network, even if it isn’t the optimal smallest it is at least smaller than it might otherwise have been.
When developing a neural network, there are four major stages:
— Design of the neural network based on needs
— Training of the neural network to find a fit
— Completion of the neural network for ongoing use
— Fielding the neural network for real-world action
At the first stage, doing design, the developer needs to consider aspects such as how many layers to have, how many neurons to have, how many synapses (connections) to have, and so on. The outermost layers are usually devoted to receiving input and providing output, and thus are for primarily externality purposes. The other layers within the neural network are sometimes called hidden layers and are in-between the outermost layers. The neurons within each layer are interconnected among other neurons in that layer, and also can be interconnected to neurons in other layers. Each neuron can have some number of fan-in connections and some number of fan-out connections.
For a given problem that you are wanting to use a neural network for, you need to be considerate about how many layers, how many neurons, how many connections, etc. If you go hog-wild and just pick some arbitrarily large sizes, you’ll likely find that the training effort can be quite high. If you go too conservative and don’t have enough size, you’ll be less likely to have the neural network be successful at trying to match to the problem and achieve the desired results.
Let’s suppose that you are devising a neural network for trying to identify street signs. This neural network will be part of the AI self-driving car system. You want the neural network to be able to accurately find street signs when an image is presented to the neural network. The self-driving car has cameras that will be taking pictures and sending those to the on-board neural network. The neural network then tries to ascertain whether there is say a Stop sign ahead, and alerts the rest of the AI system so that the self-driving car will appropriately come to a stop.
The on-board neural network will consume storage space and processor time in order to do its thing of analyzing images that come from the self-driving car cameras. The computers on-board of the self-driving car need to be powerful enough to be able to house the neural network and fast enough to ensure that the neural network will do its matching in time. If the camera provides an image of a street sign, and if the self-driving car is moving ahead at a fast speed, and if it takes the neural network too long to figure out if the sign is a Stop sign, the AI of the self-driving car might run right through the Stop sign because of the lateness of getting the street sign analysis results from the neural network.
Consider that self-driving cars need tons upon tons of neural networks for analyzing all kinds of input coming from the cameras and the LIDAR and the sonar, etc., and you begin to realize that the amount of computers needed on-board and their storage needs is rather daunting. Plus, consider too the energy requirements for all of these computers. You’ll need to have an enormous battery or other energy producing elements of the self-driving car just to power all of the computers needed on-board.
Thus, overall, it would be vital to try and keep the size of the neural networks to the least size feasible. This though must be done in a fashion that does not overly limit how well they work. If we were to prune and compress a street sign neural network so that it was tiny, but if it then did a lousy job of recognizing street signs, and suppose it could only figure out a Stop sign some of the time, we are then putting at heightened risk the rest of the self-driving car and the occupants too.
So, the developer during the design stage must try to gauge what size they think makes sense to use. Then, during the training stage, they have the neural network train on large samples of data and see how well the neural network can train onto the data. You want the neural network to reach a state of generalizability such that it will be able to work well once it is put into use. If the neural network “overfits” to the training data, it means that the neural network does well on the training set but that it will likely not do so well once it is put into use (due to becoming focused solely on the training data overly so).
After the neural network has been sufficiently trained, the developer then does some final completion aspects to get it ready for use on an ongoing basis. In some cases, the neural network will be sparse such as having swaths of neurons that are not used or connections that are not used, and so on. Most developers tend to think about pruning once they get to this completion stage of the effort. They might not realize that they already were likely doing pruning when they were in the design stage, in the sense that perhaps they initially setup the neural network at some size N that they could have done at size N+1, but instead opted to go with N. In other words, they did pruning simply by deciding at the outset what the size would be as they went into the training stage.
The point here is that you can do pruning at any of the stages. You can essentially do pruning when initially designing the neural network. Once the neural network is undergoing training, you can do pruning to see how it impacts the training. And, once the neural network is trained, during the completion stage you can do pruning. You can also do pruning once the neural network is fielded.
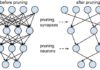
The types of pruning include:
— Prune the number of layers (this is usually the biggest bang for the buck)
— Prune the number of connections
— Prune the number of neurons
— Prune the number of weights
— Prune other aspects
If you can somehow eliminate an entire layer of the neural network then it often is the biggest bang for the buck in terms of reducing the size and complexity of the neural network. That being said, it is usually less likely that you can reduce an entire layer. Also, I don’t want to mislead in that you could have a layer that is rather skimpy to begin with, and so the amount of pruning by eliminating that layer might not be as big a payoff as if you were able to prune the number of connections, or neurons, etc. Each neural network will have its own shape and so the pruning payoff depends upon that shape.
You should also be careful about assuming that pruning is easy.
Have you ever tried to prune a tree or a bush that maybe has become overgrown around your house? Just chop away it, you at first think. If you do so, you’ll find that sometimes the tree or bush becomes so harmed that it won’t grow back. There are at times right ways and wrong ways to do pruning. This is the case too with the neural network. If you prune in the wrong ways, you’ll begin to lose the point of having the neural network at all. As such, during pruning, you need to examine how sensitive the neural network is to each of the pruning actions that you undertake.
Besides pruning, a developer should also consider how to possibly compress the neural network. For example, if you take a look at the weights used for the neurons, you can sometimes find that there are some weights that are zero (in which case those neurons are candidates possible for pruning), or that are near to zero (more candidates for pruning), or that are of a commonly repeated value that you could potentially compress them. One of the most popular compression techniques used for neural network compression is to apply Huffman coding. Essentially, the Huffman coding technique takes codes that appear frequently, such as the same weights being used over and over in the neural network, and produces an alternative code which is shorter in size, and yet will still return back the original code when needed (this is known as lossless data compression).
A handy research study on deep compression and pruning was recently done by researchers Song Han (Stanford University), Huizi Mao (Tsinghua University, Beijing), and William Dally (Stanford University), entitled “Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization, and Huffman Coding,” and provided some impressive indications of how you can potentially dramatically reduce the size of a neural network if you invoke appropriate pruning and compression approaches. One must be cautious though about how much a pruning effort or compression effort will payoff since, as mentioned already, the nature and shape of the neural network will impact whether you have a strong payoff or a weaker payoff.
In the case of AI self-driving cars, the pruning and compression is most likely to have a strong payoff for a type of neural network known as convolutional neural network, which is a type of neural network used for image analysis and visual pattern matching. We’ve seen this work well on neural networks for street sign analysis in AI self-driving cars, and also for pedestrian detection neural networks too.
For many of the AI self-driving car developers, they are primarily right now trying to make neural networks that work for the AI self-driving car, and not as concerned about whether the neural networks take up a lot of storage or consume a lot of processing time. This will become more apparent to those developers once their neural networks are working in-the-field. It is a big jump to go from a neural network that works well in the lab or in a simulation, and instead to have it work in the real world. Optimization will be key to machine learning being viable while on-board an AI self-driving car. We don’t want to have neural networks that are like a Booby Trap waiting to spring at the worst of times while a self-driving car is zooming down the freeway at 70 miles per hour. Prune and compress, that’s the lesson learned here.
This content is originally posted on AI Trends.